- A+
所属分类:未分类
本帖最后由 qqjue 于 2014-2-18 23:16 编辑
这里有几个主要关系:
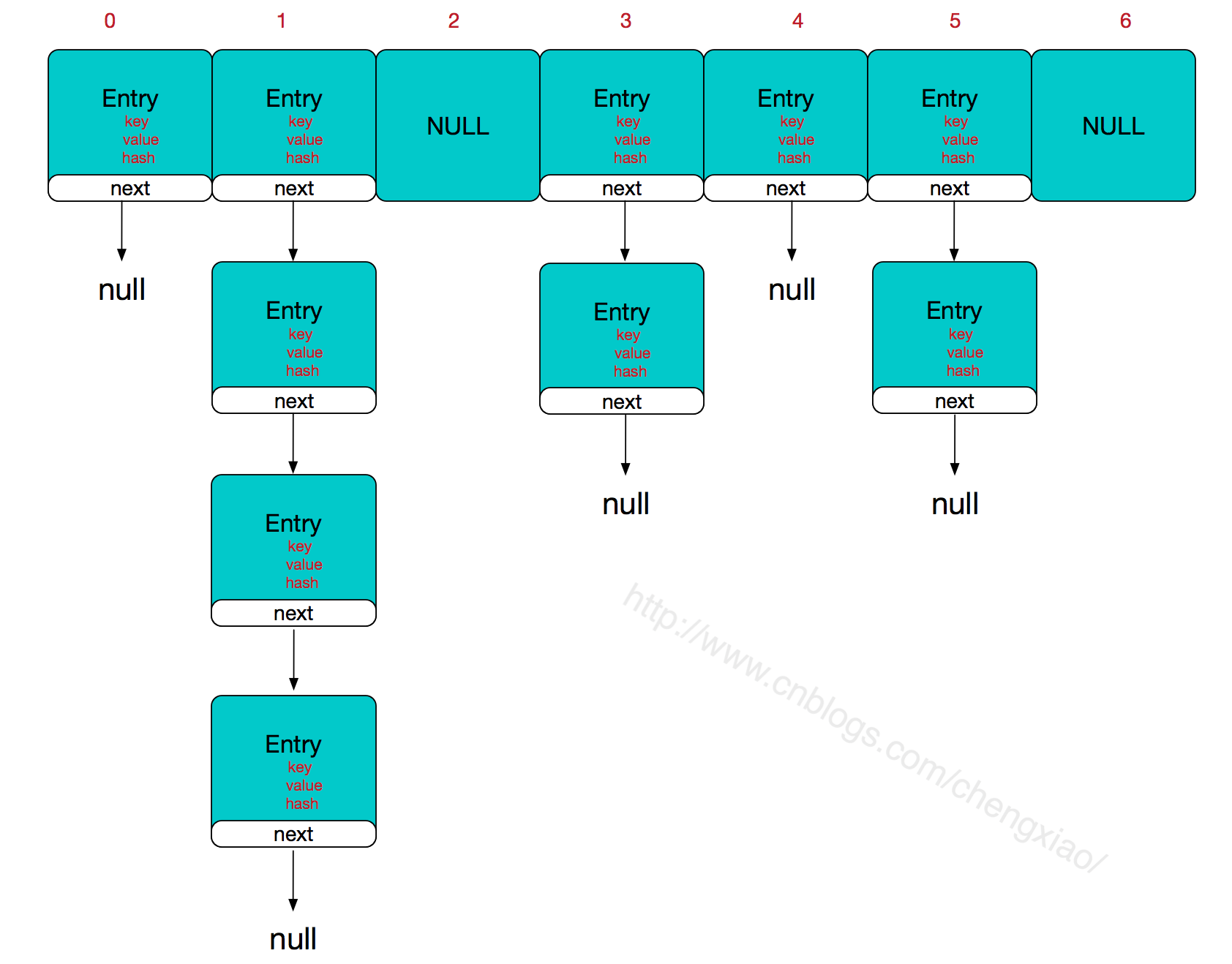
1.经过Map、Reduce运算后产生的结果看上去是被写入到HBase了,但是其实HBase中HLog和StoreFile中的文件在进行flush to disk操作时,这两个文件存储到了HDFS的DataNode中,HDFS才是永久存储。
2.ZooKeeper跟Hadoop Core、HBase有什么关系呢?ZooKeeper都提供了哪些服务呢?主要有:管理Hadoop集群中的NameNode,HBase中HBaseMaster的选举,Servers之间状态同步等。具体一点,细一点说,单只HBase中ZooKeeper实例负责的工作就有:存储HBase的Schema,实时监控HRegionServer,存储所有Region的寻址入口,当然还有最常见的功能就是保证HBase集群中只有一个Master。
2、搭建完全分布式集群
在做hadoop,hbase这方面的工作有一段时间了,经常有刚接触这些东西的身边朋友,向我询问基本环境的搭建问题,于是就想以回忆录的形式把基本配置的步骤整理出来,以便刚接触的朋友做个参考. HBase集群建立在hadoop集群基础之上,所以在搭建HBase集群之前需要把Hadoop集群搭建起来,并且要考虑二者的兼容性.现在就以四台机器为例,搭建一个简单的集群. 使用的软件版本:hadoop-1.0.3,hbase-0.94.2,zookeeper-3.4.4. 四台机器IP:10.2.11.1,10.2.11.2,10.2.11.3,10.2.11.4.
一.搭建Hadoop集群
1. 安装JDK.在每台机器下建立相同的目录/usr/Java.把下载的jdk(1.6及以上版本)复制到/usr/java目录下面,使用命令
- tar –zxvf jdk-7u9-Linux-i586.tar.gz
- sudo chmod 777 jdk-1.7.0_09
把jdk的路径加到环境变量中:
- vim.tiny /etc/profile
在该文件最后一行添加:
- JAVA_HOME=/usr/java/jdk1.7.0_09
- PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:PATH
- CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
使修改的操作生效:
- source /etc/profile
可以使用
- java -version
进行验证是否已配置成功. 2.在每台机器上建立相同的用户名
- sudo adduser cloud
- password cloud
输入你要设置的密码.然后在每台机器作配置:
- sudo gedit /etc/hosts
打开文件后加入如下内容:
- 10.2.11.1 namenode
- 10.2.11.2 datanode1
- 10.2.11.3 datanode2
- 10.2.11.4 datanode3
3.在/home/cloud/目录下建立一个文件夹project,命令如下:
- mkdir project
把hadoop-1.0.3.tar.gz,zookeeper-3.4.4.tar.gz,hbase-0.94.2.tar.gz,这些下载的软件包放在此目录下面,以待下一步操作。 4.使用命令
- tar –zxvf hadoop-1.0.3.tar.gz
进行解压文件.进入配置目录,开始配置.
- cd hadoop-1.0.3/conf
5. 使用命令 : vim.tiny hadoop-env.sh 把java的安装路径加进去:
- JAVA_HOME=/usr/java/jdk1.7.0_09/
6. vim.tiny core-site.xml ,加入如下配置:
- hadoop.tmp.dir
- /home/cloud/project/tmp
- </property >
- < property >
- fs.default.name
- hdfs://namenode:9000
- </property >
7. vim.tiny hdfs-site.xml,加入如下配置:
- dfs.repplication
- 3
- </property >
- dfs.data.dir
- /home/cloud/project/tmp/data
- </ property >
8. gedit mapred-site.xml,添加如下内容:
- mapred.job.tracker
- namenode:9001
- </property >
9. gedit master,加入如下配置内容:
- namenode
10. gedit slaves,加入如下配置内容:
- datanode1
- datanode2
- datanode3
11. 配置机器之间无密码登陆.在每台机器下建立相同目录 .ssh ,如
- mkdir /home/cloud/.ssh
在namenode节点下,使用命令ssh-keygen –t rsa,然后一直回车(中间不用输入任何其他信息),直到结束,然后使用命令cd .ssh,
- cp id_rsa.pub authorized.keys
使用远程传输,把authorized.keys分别复制到其他机器的.ssh目录下面,命令如下:
- scp authorized_keys datanode1:/home/cloud/.ssh
- scp authorized_keys datanode2:/home/cloud/.ssh
- scp authorized_keys datanode3:/home/cloud/.ssh
进入每台机器的.ssh目录下修改authorized_keys的权限,命令如下:
- chmod 644 authorized_keys
12.把配置好的hadoop分别拷贝到集群中其他机器上,命令如下:
- scp –r hadoop-1.0.3 datanode1:/home/cloud/project
- scp –r hadoop-1.0.3 datanode2:/home/cloud/project
- scp –r hadoop-1.0.3 datanode3:/home/cloud/project
13.在namenode机器下,进入hadoop的安装目录,对文件系统进行格式化:
- bin/hadoop namenode –format
14. 启动集群: bin/start-all.sh. 可以使用
- bin/hadoop dfsadmin –report
查看文件系统的使用情况。 使用命令
- jps
查看节点服务启动情况,正常情况有:jobtracker、namenode、jps、secondnamenode.否则启动异常,重新检查安装步骤。
二.安装zookeeper
1.在namenode机器下,配置zookeeper,先解压安装包,使用命令:
- tar -zxvf zookeeper-3.4.4.tar.gz
2.进入zookeeper的配置目录,首先把zoo_sample.cfg重命名一下,可以重新复制一遍,使用命令:
- cp zoo_sample.cfg zoo.cfg
3.gedit zoo.cfg ,添加如下内容:
- dataDir=/home/cloud/project/tmp/zookeeper/data
- server.1 = datanode1:7000:7001
- server.2 =datanode2:7000:7001
- server.3 =datanode3:7000:7001
4.把zookeeper分别远程拷贝datanode1,datanode2,datenode3,使用如下命令:
- scp –r zookeeper-3.4.4 datanode1:/home/cloud/project
- scp –r zookeeper-3.4.4 datanode2:/home/cloud/project
- scp –r zookeeper-3.4.4 datanode3:/home/cloud/project
5.分别在刚才的datanode节点/home/cloud/project/tmp/zookeeper/data目录下,新建文件myid,然后使用命令
- vim.tiny myid
分别在datanode1,datanode2,datanode3的myid中写入对应的server.n中的n,即分别是1,2,3.
6.开启zookeeper服务,在三台datanode机器的zookeeper安装目录下使用命令:
- bin/zkServer.sh start
三.部署hbase
1.解压缩hbase的软件包,使用命令:
- tar -zxvf hbase-0.94.2.tar.gz
2.进入hbase的配置目录,在hbase-env.sh文件里面加入java环境变量.即:
- JAVA_HOME=/usr/java/jdk1.7.0_09/
加入变量:
- export HBASE_MANAGES_ZK=false
3. 编辑hbase-site.xml ,添加配置文件:
- hbase.rootdir
- hdfs://namenode:9000/hbase
- hbase.cluster.distributed
- true
- hbase.zookeeper.quorum
- datanode1,datanode2,datanode3
- hbase.zookeeper.property.dataDir
- /home/cloud/project/tmp/zookeeper/data
4. 编辑配置目录下面的文件regionservers. 命令:
- vim.tiny regionservers
加入如下内容:
- datanode1
- datanode2
- datandoe3
5. 把Hbase复制到其他机器,命令如下:
- scp -r hbase-0.94.2 datanode1:/home/cloud/project
- scp -r hbase-0.94.2 datanode2:/home/cloud/project
- scp -r hbase-0.94.2 datanode3:/home/cloud/project
6. 开启hbase服务。命令如下:
- bin/start-hbase.sh
可以使用bin/hbaseshell 进入hbase自带的shell环境,然后使用命令version等,进行查看hbase信息及建立表等操作。