- A+
MySQL索引机制
永远年轻,永远热泪盈眶
一.索引的类型与常见的操作
-
前缀索引
MySQL 前缀索引能有效减小索引文件的大小,提高索引的速度。但是前缀索引也有它的坏处:MySQL 不能在 ORDER BY 或 GROUP BY 中使用前缀索引,也不能把它们用作覆盖索引(Covering Index)。
-
复合索引
集一个索引包含多个列(最左前缀匹配原则)
-
唯一索引
索引列的值必须唯一,但允许有空值
-
全文索引
在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎.在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词.
全文索引为FUllText,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值,全文索引可以在CHAR,VARCHAR,TEXT类型列上创建
-
主键索引
设定主键后数据会自动建立索引,InnoDB为聚簇索引
-
单列索引
即一个索引只包含单个列,一个表可以有多个单列索引
-
覆盖索引
覆盖索引是指一个查询语句的执行只用从所有就能够得到,不必从数据表中读取,覆盖索引不是索引树,是一个结果,当一条查询语句符合覆盖索引条件时候,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后的回表操作,减少了I/O效率
-- 目前有一个key(name)索引,聚簇索引是key(id) -- 使用了覆盖索引 select id from stu where key = '天天'; -- 不使用覆盖索引,因为查询的结果无法从普通索引树中得到 select * from stu where key = '天天'
查看索引
show index from table_name;

列名解析:
| 列名title | 解释desc | 取值value |
|---|---|---|
| table | 索引对应表的名称 | DB中的表 |
| Non_unique | 索引包含value是否为唯一(是否为唯一索引) | 0代表是唯一,1代表不是 |
| Key_name | 索引的名称 | 不命名为创建时列名称,联合查询为Seq_in_index为1的列名称,重复是使用_+number区分 |
| Seq_in_index | 索引中列的序列号,从1开始,表明在联合查询中的顺序,我们可以根据这个推断出联合索引中索引的前后顺序(使用最左优化原则) | 从1递增至联合索引的列数 |
| Column_name | 索引的列名 | 索引的列名 |
| Collation(n.排序方式,校队) | 指排序方式 | A表示升序,B表示降序,NULL表示未排序。 |
| Cardinality | 基数的意思,表示索引中唯一值的数目的估计值,我们知道某个字段的重复值越少越适合建立索引,所以我们一般根据Cardinality来判断索引是否具有高选择性,如果这个值非常小,就需要评估这个字段是否适合做索引 | 最小值为1,表示索引的列字段值都重复,最大为表中字段数 |
| Sub_part | 当索引是前缀索引的时候,sub_part表示前缀的字符数 | 非前缀为0,前缀索引为字符数 |
| Packed | 指示关键字如何被压缩。 | 如果没有被压缩,则为NULL |
| NUll | 如果列含有null,则含有yes | null/yes |
| Index_type | 表示索引类型,全文索引是Fulltext,Memory引擎对应Hash,其他大多数是Btree,Rtree没有见过 | FULLTEXT,HASH,BTREE,RTREE |
| Comment | 注释 | ... |
| Index_comment | 注释 | ... |
删除索引
drop index index_name on table name;
-- 错误删除primary索引
drop index `PriMary` on temp;
-- >:Incorrect table definition; there can be only one auto column and it must be defined as a key
二.常见的索引详解与创建
-
主键索引
-- mysql中InnoDB使用主键索引作为聚簇索引,主键索引无法使用 -- 创建时候,主键自动定义 create table temppp(id int auto_increment,primary key(id),name varchar(20) not null unique); -- 无法删除primary key索引,需要改变的时候,首先需要删除主键列,删除后自动选择一行unique的列作为主键索引 alter table temppp drop COLUMN id; 查看:

删除前:

删除后:

-
单列索引
普通的索引,没有什么介绍
-- 建表时候表级约束建立索引 create table otest( id int(25) PRIMARY key, `name` varchar(255), -- 这一句就是在建立普通字段的索引,但是无法设置名字 key(`name`) ) -- 建表后 alter table otest add index key(`name`); 查看:(注意和前缀索引Sub_part的区别)

-
唯一索引
当索引的列是unique的时候,会生成唯一索引,唯一索引关于null有下列两种情况

-- 插入两条null语句 insert into temp values(1,null); insert into temp values(2,null); 结果:

-
MYSQL下的唯一索引的列,允许null值,并且允许多个空值
-- mysql下实验代码 create table otest ( id int primary key, age varchar(20) unique, key(age) ); show index from otest 查看:

会建立两个索引,一个非聚簇索引,一个是唯一索引
-- 插入两条null语句 ....与上代码相似 结果:

可以插入两个空值(明人不说暗话,我喜欢MySQL)
-
SQLSERVER 下的唯一索引的列,允许null值,但最多允许有一个空值
-- sql server 下实验代码 create table temp ( id int primary key, age varchar(20) unique, ); create unique index age on temp(age) execute sp_helpindex @objname='temp' 查看:
-
前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length)); -- 表级创建 create table temppp (id int auto_increment,primary key(id), name varchar(20) not null unique, key(name(2))); -- 表级创建 alter table temppp add index(name(2)) 查看:
-
一方面,它不会索引所有字段所有字符,会减小索引树的大小.
-
另外一方面,索引只是为了区别出值,对于某些列,可能前几位区别很大,我们就可以使用前缀索引。
-
一般情况下某个前缀的选择性也是足够高的,足以满足查询性能。对于BLOB,TEXT,或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。

前缀索引实例的博文:https://www.jianshu.com/p/fc80445044cc 很好,推荐
-
复合索引
-- 建表时候表级约束建立索引 drop table if exists `otest`; create table otest( id int(25) PRIMARY key, `name` varchar(255), age varchar(255), -- 这一句就是在建立普通字段的索引,但是无法设置名字 key(`name`,age) ); -- 建表后 alter table otest add key(`name`,age); 查看:

复合索引的最左前缀匹配原则:
对于复合索引,查询在一定条件才会使用该索引
-- 假设一个下列的索引 alter table otest add index(id,name,age); -- 只有查询条件满足组合索引的前缀匹配才能使用索引,也就是对于查询的顺序为 -- id id,name id,name,age这三种情况下才能使用组合索引 -- 对于下列这种就无法使用索引 select * from otest where id=?,age=? -- 缺少了name列 select * from otest where name=?,age=? -- 缺少了id列 -- 对于下列查询MySQL会使用优化调整位置 select * from otest where id=?,age=?,name=? -- 查询顺序是 id,age,name看起来是不能使用索引的,但是MySQL在执行的时候会进行优化,将顺序调整为id name age。 复合索引的优点
减少开销。建一个联合索引(col1,col2,col3),实际相当于建了(col1),(col1,col2),(col1,col2,col3)三个索引。每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,使用联合索引会大大的减少开销!
覆盖索引。对联合索引(col1,col2,col3),如果有如下的sql: select col1,col2,col3 from test where col1=1 and col2=2。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一。
效率高。索引列越多,通过索引筛选出的数据越少。有1000W条数据的表,有如下sql:select from table where col1=1 and col2=2 and col3=3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w条数据,然后再回表从100w条数据中找到符合col2=2 and col3= 3的数据,然后再排序,再分页;如果是联合索引,通过索引筛选出1000w10% 10% *10%=1w。
-
全文索引(FULLTEXT)
在模糊搜索中很有效,搜索全文中的某一个字段,可以参考这篇博文:https://zhuanlan.zhihu.com/p/88275060
三.索引的原理
1.通过实验介绍B+tree
我们先进行下面一个实验看看InnoDB下的主键索引的一个现象。
create table otest(
id int(25) PRIMARY key,
`name` varchar(255),
age varchar(255)
);
insert into otest values(3,'q',1);
insert into otest values(1,'q',1);
insert into otest values(5,'q',1);
insert into otest values(2,'q',1);
insert into otest values(6,'q',1)
-- 查看现象
SELECT * from otest
查看:
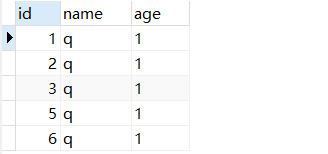
我们插入进去的时候,数据的id都是乱序的,为什么这里最后select查询出来的结果都是进行了排序?
这是因为InnoDB索引底层实现的是B+tree,B+tree具有下列的特点:
-
和B-tree一样是自平衡树
-
m个子树上层有m个中间节点,但是m个中间节点只保存索引,而不保存数据。
-
所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大的顺序链接。
-
所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键字。
所以上面的排序是为了使用B+tree的结构,B+tree为了范围搜索,将主键按照从小到大排序后,拆分成节点。后续还有新的节点进入的时候,和B-tree相同的操作,会进行分裂。
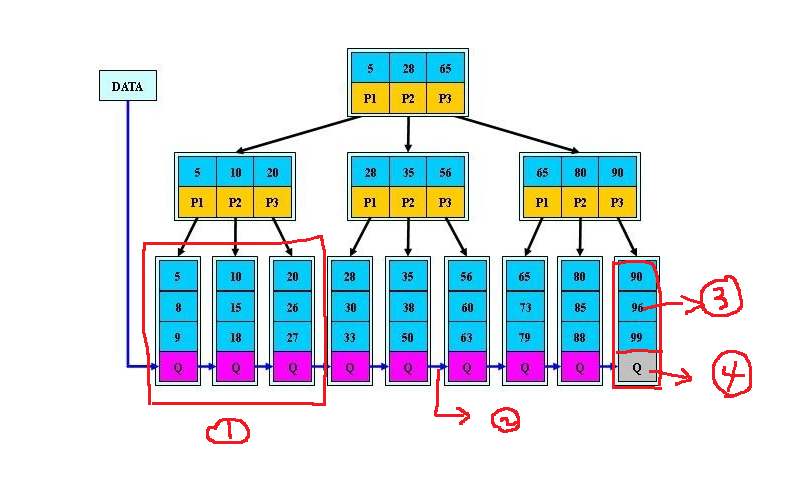
一般来说,聚簇索引的B+tree都是三层
-
①:每一个底层片称为一个页,InnoDB中一个页的大小默认是16kb,上层的中间结点称为页目录,每个页目录都有一个指针指向下层存储数据的叶结点
-
②:下层每个叶结点之间都使用链表连接(ps:这里是单链表还是双向链表我记不清楚了,读者可以查查)
-
③:这部分是叶结点存储的数据信息
-
④:这部分是底层链表的指针
2.延伸
-
B-tree是所有结点都要存储数据,相同的数据更深,查找速度变慢,所以底层没有使用B-tree。
-
MySQL的InnoDB存储引擎设计时顶层页目录常驻内存,对于2-4层B+树查询时,聚簇索引IO查询1-3次,也就是和硬盘交互进行IO读
-
计算一个元素的字节大小:**字段类型所占字节 + 一个指针的字节数(32位4byte,64位8byte)
-
实际单表列过多要拆表,这样主表存数据更多深度也低,查询也快
-
对于InnoDB来说主键索引就是聚簇索引,而普通索引就是非聚簇索引
-
对于表中数据操作过多会造成存在许多的页碎片,关于碎片整理可以看我这篇博文
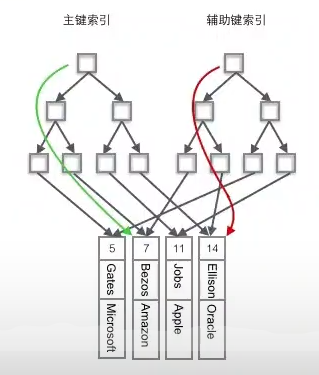
四.聚簇索引和非聚簇索引
-
聚簇索引:将数据存储和索引放到了一块,索引结构的叶子结点保存了行数据
-
非聚簇索引:将数据与索引分开存储,索引结构的叶子结点指向主键的值,也就是对应的聚簇索引的row id(需要查找两个B+tree,这个操作过程叫做回表)。
InnoDB中主键索引一定是聚簇索引,聚簇索引一定是主键索引。
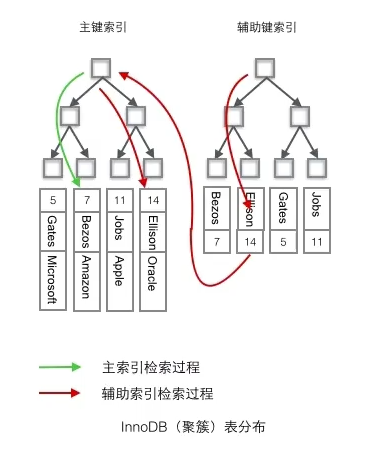
为什么这里辅助索引叶子结点不直接存储数据呢?
-
数据冗余
-
修改,增加,删除需要操作的更多,时间线性增加,也就是难以维护
-
占用磁盘存储增大
MYISAM只有非聚簇索引,索引最终指向的都是物理地址。
1.使用聚簇索引的优势
Q:既然有回表的存在,那么聚簇索引的优势在哪里?
-
由于行数据和聚簇索引的叶子结点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把也加载到了buffer中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘,这样主键和行数据是一起被载入内存的,找到叶子结点就可以立刻将行数据返回了,获得数据更快。
-
辅助索引的叶子结点,存储主键值,而不是数据的存放地址,好处是当行数据发生变化时,索引树的节点也需要分裂变化,或者是我们需要查找的数据,在上一次读写的缓存中没有,需要发送一次新的IO操作时,可以避免对辅助索引的维护工作,只要维护聚簇索引树就好了,另外一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间的大小。
Q:主键索引作为聚簇索引需要注意什么
-
当使用主键为聚簇索引时,主键最好不要使用UUID,因为UUID的值过于离散(可以查看UUID的产生过程),不适合排序,并且可能在两个已经排序好的结点中会出现新插入的节点,导致索引树调整复杂度变大。
-
建议使用int类型的自增,int类型自增主键数据量为4亿,满足一般开发要求,并且由于自增,主键本身就有序,因此开销很小,辅助索引中保存的主键值也会跟着变化,占用存储空间,也会影响到IO操作读取到的数据量。
2.什么情况下无法使用索引
-
查询语句中使用Like关键字
在查询语句中使用LIke关键字进行查询时,如果匹配字符串的第一个字符为"%",索引不会使用。如果“%”不是在第一位,索引就会使用
-
查询语句中使用多列索引
多列索引是在表的多个字段上创建的索引,满足最左前缀匹配原则,索引才会被使用
-
查询语句中使用OR关键字
查询语句只有Or关键字时候,如果OR前后的两个条件都是索引,这这次查询将会使用索引,否则Or前后有一个条件的列不是索引,那么查询中将不使用索引
5.关于Explain语句
作者不会,建议查找,这里列出是作为提醒
永远年轻,永远热泪盈眶
TIPS:MySQL底层存储文件:
MyISAM:.frm是存放表结构的文件,.MYD是存放表数据的文件,.MYI是存放表索引的文件
InnoDB:.frm存放表结构,.Ibd是存放表数据和索引的