- A+
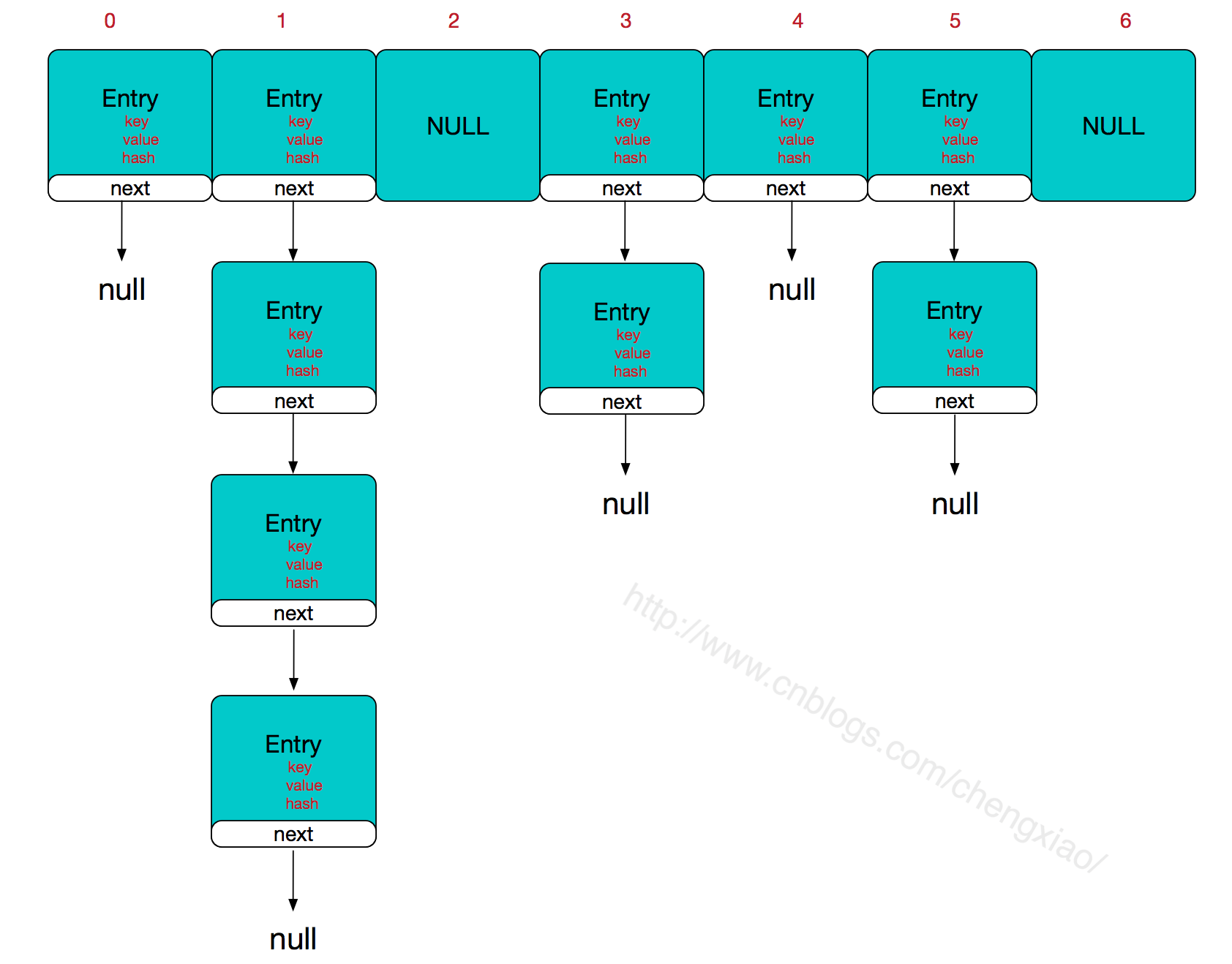
一 作业分片
1.分片概念
作业分片是指任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的应用实例分别执行某
一个或几个分片项。
例如:Elastic-Job快速入门中文件备份的例子,现有2台服务器,每台服务器分别跑一个应用实例。为了快速的执
行作业,那么可以将作业分成4片,每个应用实例个执行2片。作业遍历数据的逻辑应为:实例1查找text和image
类型文件执行备份;实例2查找radio和video类型文件执行备份。 如果由于服务器扩容应用实例数量增加为4,则
作业遍历数据的逻辑应为:4个实例分别处理text、image、radio、video类型的文件。
可以看到,通过对任务合理的分片化,从而达到任务并行处理的效果,最大限度的提高执行作业的吞吐量。
分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处
理分片项与真实数据的对应关系。
最大限度利用资源
将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配
分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C
崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,最大限度的利用现
有资源提高吞吐量。
2.作业分片实现
基于Spring boot集成方式的而产出的工程代码,完成对作业分片的实现,文件数据备份采取更接近真实项目的数
据库存取方式。
CREATE DATABASE `elastic_job_demo` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';

DROP TABLE IF EXISTS `t_file`; CREATE TABLE `t_file` ( `id` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `content` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `backedUp` tinyint(1) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
pom文件
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.15</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- https://mvnrepository.com/artifact/com.dangdang/elastic-job-lite-spring --> <dependency> <groupId>com.dangdang</groupId> <artifactId>elastic-job-lite-spring</artifactId> <version>2.1.5</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> </dependency> </dependencies>
开发类
@Configuration
public class ElasticJobConfig {
@Autowired
private DataSource dataSource; //数据源已经存在,直接引入
// @Autowired
// SimpleJob fileBackupJob;
@Autowired
FileBackupJobDb fileBackupJob;
// @Autowired
// FileBackupJobDataFlow fileBackupJob;
@Autowired
CoordinatorRegistryCenter registryCenter;
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob> jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters){
//JobCoreConfigurationBuilder
JobCoreConfiguration.Builder JobCoreConfigurationBuilder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
//设置shardingItemParameters
if(!StringUtils.isEmpty(shardingItemParameters)){
JobCoreConfigurationBuilder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration jobCoreConfiguration = JobCoreConfigurationBuilder.build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, jobClass.getCanonicalName());
//创建LiteJobConfiguration
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true)
.monitorPort(9888)//设置dump端口
.build();
return liteJobConfiguration;
}
//创建支持dataFlow类型的作业的配置信息
private LiteJobConfiguration createFlowJobConfiguration(final Class<? extends ElasticJob> jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters){
//JobCoreConfigurationBuilder
JobCoreConfiguration.Builder JobCoreConfigurationBuilder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
//设置shardingItemParameters
if(!StringUtils.isEmpty(shardingItemParameters)){
JobCoreConfigurationBuilder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration jobCoreConfiguration = JobCoreConfigurationBuilder.build();
// 定义数据流类型任务配置
DataflowJobConfiguration jobConfig = new DataflowJobConfiguration(jobCoreConfiguration, jobClass.getCanonicalName(),true);
//创建LiteJobConfiguration
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(jobConfig).overwrite(true)
// .monitorPort(9888)//设置dump端口
.build();
return liteJobConfiguration;
}
@Bean(initMethod = "init")
public SpringJobScheduler initSimpleElasticJob() {
// 增加任务事件追踪配置
JobEventConfiguration jobEventConfig = new JobEventRdbConfiguration(dataSource);
//创建SpringJobScheduler
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileBackupJob, registryCenter,
createJobConfiguration(fileBackupJob.getClass(), "0/3 * * * * ?", 1, "0=text,1=image,2=radio,3=vedio")
,jobEventConfig);
return springJobScheduler;
}
}
@Configuration
public class ElasticJobRegistryCenterConfig {
//zookeeper链接字符串 localhost:2181
private String ZOOKEEPER_CONNECTION_STRING = "192.168.180.113:2181" ;
//定时任务命名空间
private String JOB_NAMESPACE = "elastic-job-boot-java";
//zk的配置及创建注册中心
@Bean(initMethod = "init")
public CoordinatorRegistryCenter setUpRegistryCenter(){
//zk的配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING, JOB_NAMESPACE);
zookeeperConfiguration.setSessionTimeoutMilliseconds(1000);
//创建注册中心
CoordinatorRegistryCenter zookeeperRegistryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
return zookeeperRegistryCenter;
}
}
Job类
@Component
public class FileBackupJob implements SimpleJob {
//每次任务执行要备份文件的数量
private final int FETCH_SIZE = 1;
//文件列表(模拟)
public static List<FileCustom> files = new ArrayList<>();
static {
for(int i=1;i<11;i++){
FileBackupJob.files.add(new FileCustom(String.valueOf(i+10),"文件"+(i+10),"text","content"+ (i+10)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+20),"文件"+(i+20),"image","content"+ (i+20)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+30),"文件"+(i+30),"radio","content"+ (i+30)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+40),"文件"+(i+40),"video","content"+ (i+40)));
}
System.out.println("生产测试数据完成");
}
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片:"+shardingContext.getShardingItem());
//分片参数,(0=text,1=image,2=radio,3=vedio,参数就是text、image...)
String jobParameter = shardingContext.getJobParameter();
//获取未备份的文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
/**
* 获取未备份的文件
* @param count 文件数量
* @return
*/
public List<FileCustom> fetchUnBackupFiles(int count){
//获取的文件列表
List<FileCustom> fileCustoms = new ArrayList<>();
int num=0;
for(FileCustom fileCustom:files){
if(num >=count){
break;
}
if(!fileCustom.getBackedUp()){
fileCustoms.add(fileCustom);
num ++;
}
}
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),num);
return fileCustoms;
}
/**
* 文件备份
* @param files
*/
public void backupFiles(List<FileCustom> files){
for(FileCustom fileCustom:files){
fileCustom.setBackedUp(true);
System.out.printf("time:%s,备份文件,名称:%s,类型:%s\n", LocalDateTime.now(),fileCustom.getName(),fileCustom.getType());
}
}
}
@Component
public class FileBackupJobDb implements SimpleJob {
//每次任务执行要备份文件的数量
private final int FETCH_SIZE = 1;
@Autowired
FileService fileService;
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片:"+shardingContext.getShardingItem());
//分片参数,(0=text,1=image,2=radio,3=vedio,参数就是text、image...)
String jobParameter = shardingContext.getShardingParameter();
//获取未备份的文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(jobParameter,FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
/**
* 获取未备份的文件
* @param count 文件数量
* @return
*/
public List<FileCustom> fetchUnBackupFiles(String fileType,int count){
List<FileCustom> fileCustoms = fileService.fetchUnBackupFiles(fileType, count);
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),count);
return fileCustoms;
}
/**
* 文件备份
* @param files
*/
public void backupFiles(List<FileCustom> files){
fileService.backupFiles(files);
}
}
模型类
@Data
@NoArgsConstructor
public class FileCustom {
/**
* 标识
*/
private String id;
/**
* 文件名
*/
private String name;
/**
* 文件类型,如text、image、radio、vedio
*/
private String type;
/**
* 文件内容
*/
private String content;
/**
* 是否已备份
*/
private Boolean backedUp = false;
public FileCustom(String id, String name, String type, String content){
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
Service类
@Service
public class FileService {
@Autowired
JdbcTemplate jdbcTemplate;
/**
* 获取某文件类型未备份的文件
* @param fileType 文件类型
* @param count 获取条数
* @return
*/
public List<FileCustom> fetchUnBackupFiles(String fileType, Integer count){
String sql="select * from t_file where type = ? and backedUp = 0 limit 0,?";
List<FileCustom> files = jdbcTemplate.query(sql, new Object[]{fileType, count}, new BeanPropertyRowMapper(FileCustom.class));
return files;
}
/**
* 备份文件
* @param files 要备份的文件
*/
public void backupFiles(List<FileCustom> files){
for(FileCustom fileCustom:files){
String sql="update t_file set backedUp = 1 where id = ?";
jdbcTemplate.update(sql,new Object[]{fileCustom.getId()});
System.out.println(String.format("线程 %d | 已备份文件:%s 文件类型:%s"
,Thread.currentThread().getId()
,fileCustom.getName()
,fileCustom.getType()));
}
}
}
application.yml
spring: datasource: url: jdbc:mysql://localhost:3306/elastic_job_demo?serverTimezone=UTC username : root password : 123456 driver-class-name: com.mysql.jdbc.Driver
启动类
@SpringBootApplication
public class ElasticJobApplication {
public static void main(String[] args) {
SpringApplication.run(ElasticJobApplication.class, args);
}
}
测试类,往数据库插入数据
@RunWith(SpringRunner.class)
@SpringBootTest
class ElasticJobApplicationTests {
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void testGenerateTestData(){
//清除数据
clearTestFiles();
//制造数据
generateTestFiles();
}
/**
* 清除模拟数据
*/
public void clearTestFiles(){
jdbcTemplate.update("delete from t_file");
}
/**
* 创建模拟数据
*/
public void generateTestFiles(){
List<FileCustom> files =new ArrayList<>();
for(int i=1;i<11;i++){
files.add(new FileCustom(String.valueOf(i),"文件"+ i,"text","content"+ i));
files.add(new FileCustom(String.valueOf((i+10)),"文件"+(i+10),"image","content"+ (i+10)));
files.add(new FileCustom(String.valueOf((i+20)),"文件"+(i+20),"radio","content"+ (i+20)));
files.add(new FileCustom(String.valueOf((i+30)),"文件"+(i+30),"vedio","content"+ (i+30)));
}
for(FileCustom file : files){
jdbcTemplate.update("insert into t_file (id,name,type,content,backedUp) values (?,?,?,?,?)",
new Object[]{file.getId(),file.getName(),file.getType(),file.getContent(),file.getBackedUp()});
}
}
}
当只开一个窗口
作业分片:1 作业分片:0 作业分片:3 作业分片:2 time:2019-12-19T16:12:02.614,获取文件1个 time:2019-12-19T16:12:02.614,获取文件1个 time:2019-12-19T16:12:02.614,获取文件1个 time:2019-12-19T16:12:02.614,获取文件1个 线程 109 | 已备份文件:文件31 文件类型:vedio 线程 108 | 已备份文件:文件21 文件类型:radio 线程 106 | 已备份文件:文件1 文件类型:text 线程 107 | 已备份文件:文件11 文件类型:image 作业分片:0 作业分片:1 作业分片:2 作业分片:3 time:2019-12-19T16:12:10.059,获取文件1个 线程 118 | 已备份文件:文件12 文件类型:image time:2019-12-19T16:12:12.411,获取文件1个 time:2019-12-19T16:12:12.428,获取文件1个 线程 117 | 已备份文件:文件2 文件类型:text time:2019-12-19T16:12:12.438,获取文件1个 线程 119 | 已备份文件:文件22 文件类型:radio 线程 120 | 已备份文件:文件32 文件类型:vedio
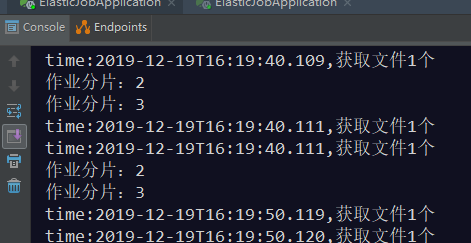
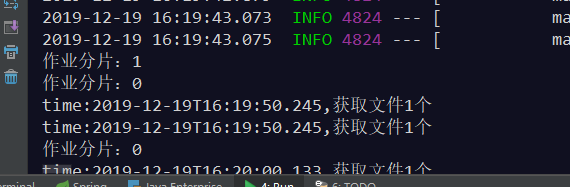
当开2个窗口的时候,结果如下:
当开3个窗口的时候,结果如下:
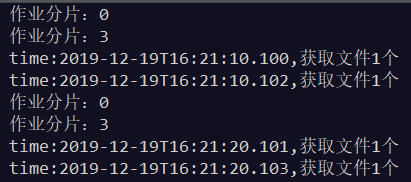
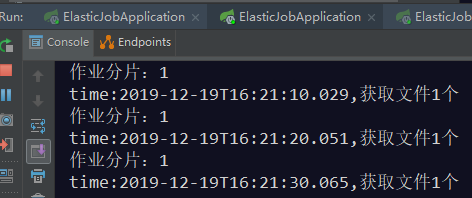
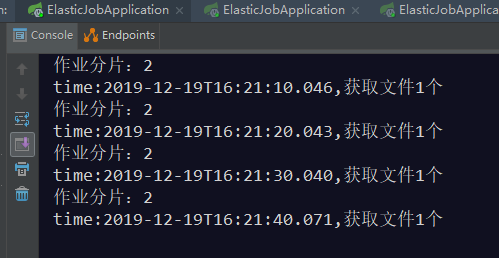
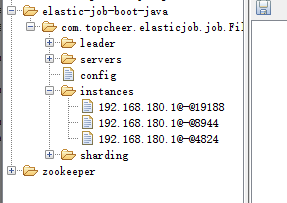
查看控制台输出可以得出如下结论: 1、任务运行期间,如果有新机器加入,则会立刻触发分片机制,将任务相对
平均的分配到每台机器上并行执行调度。 2、如果有机器退出集群,则经过短暂的一段时间(大约40秒)后又会重
新触发分片机制
如果在设置zookeeper注册中心时,设置了session超时时间100 毫秒,则下次任务前就会触发分片
@Bean(initMethod = "init")
public CoordinatorRegistryCenter createRegistryCenter() {
ZookeeperConfiguration zkConfig = new ZookeeperConfiguration(registryServerList,
registryNamespace);
zkConfig.setSessionTimeoutMilliseconds(100);//这里设置了session超时时间100 毫秒
CoordinatorRegistryCenter regCenter = new ZookeeperRegistryCenter(zkConfig);
return regCenter;
}
如果在sessionTimeoutMs的时间段之内触发任务,则异常分片的任务会丢失。举个例子:假如
sessionTimeoutMs被设置成1分钟,而本身的任务是30秒执行一次,有三个任务实例在三台机器各自执行分片
1,2,3。当分片3所在的机器出现问题,和zookeeper断开了,那么zookeeper节点失效至少要到1分钟以后。期间30
秒执行一次的任务分片3,至少会少执行一次。1分钟过后,zookeeper节点失效,触发
ListenServersChangedJobListener类的dataChanged方法,在这里方法中判断instance节点变化,然后通过方法
shardingService.setReshardingFlag设置重新分片标志位,下次执行任务的时候,leader节点重新分配分片,分片
3就会转移到其他好的机器上。
3.作业分片策略
AverageAllocationJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。如:
如果有3台服务器,分成9片,则每台服务器分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
OdevitySortByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.OdevitySortByNameJobShardingStrategy
策略说明:
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP升序。
作业名的哈希值为偶数则IP降序。
用于不同的作业平均分配负载至不同的服务器。
AverageAllocationJobShardingStrategy的缺点是,一旦分片数小于作业服务器数,作业将永远分配至IP地址靠前
的服务器,导致IP地址靠后的服务器空闲。而OdevitySortByNameJobShardingStrategy则可以根据作业名称重新
分配服务器负载。如:
如果有3台服务器,分成2片,作业名称的哈希值为奇数,则每台服务器分到的分片是:1=[0], 2=[1], 3=[]
如果有3台服务器,分成2片,作业名称的哈希值为偶数,则每台服务器分到的分片是:3=[0], 2=[1], 1=[]
RotateServerByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.RotateServerByNameJobShardingStrategy
策略说明:
根据作业名的哈希值对服务器列表进行轮转的分片策略。
配置分片策略
与配置通常的作业属性相同,在spring命名空间或者JobConfiguration中配置jobShardingStrategyClass属性,属
性值是作业分片策略类的全路径。
分片策略配置xml方式:
<job:simple id="hotelSimpleSpringJob" class="com.chuanzhi.spiderhotel.job.SpiderJob" registry‐ center‐ref="regCenter" cron="0/10 * * * * ?" sharding‐total‐count="4" sharding‐item‐ parameters="0=A,1=B,2=C,3=D" monitor‐port="9888" reconcile‐interval‐minutes="10" job‐sharding‐ strategy‐ class="com.dangdang.ddframe.job.lite.api.strategy.impl.RotateServerByNameJobShardingStrategy"/>
分片策略配置java方式:
// 定义Lite作业根配置
JobRootConfiguration simpleJobRootConfig =
LiteJobConfiguration.newBuilder(simpleJobConfig).jobShardingStrategyClass("com.dangdang.ddframe.
job.lite.api.strategy.impl.OdevitySortByNameJobShardingStrategy").build();
4.Elastic-Job 高级
4.1 事件追踪
Elastic-Job-Lite在配置中提供了JobEventConfiguration,支持数据库方式配置,会在数据库中自动创建
JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引,来记录作业的相关信息。
4.1.2.启动项目
启动后会发现在elastic_job_demo数据库中新增以下两个表。
job_execution_log:
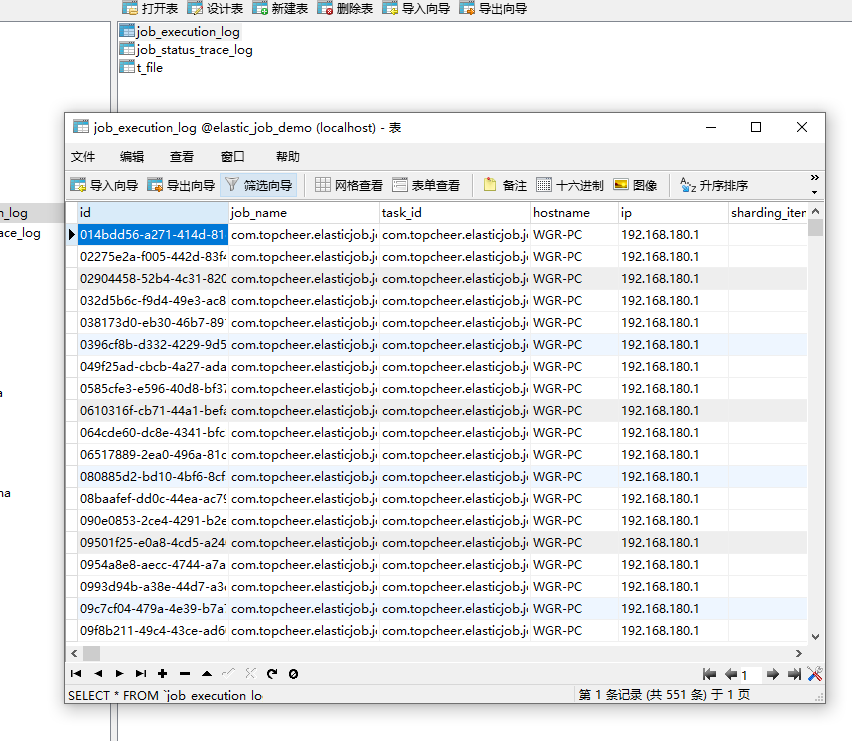
job_status_trace_log:
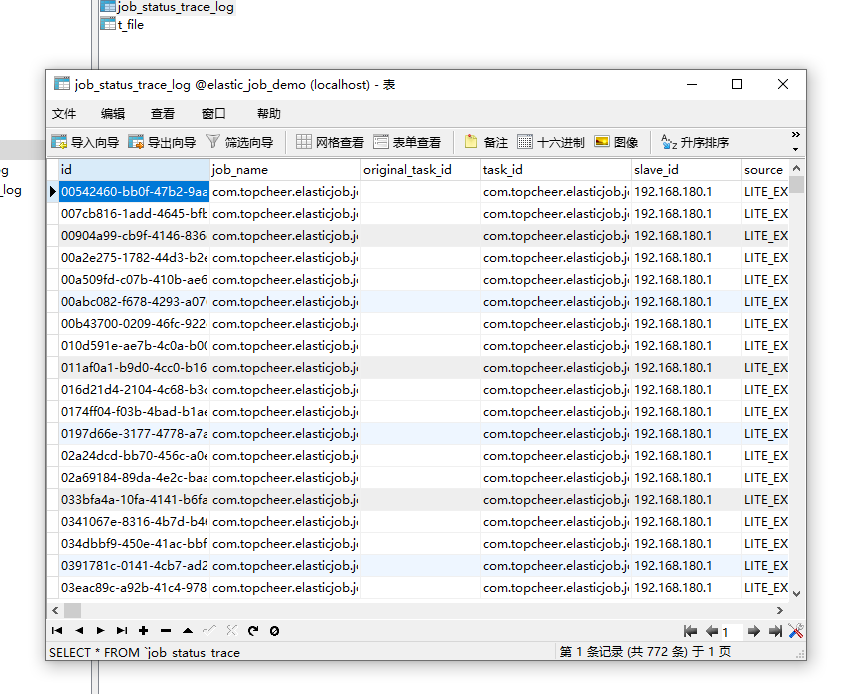
JOB_EXECUTION_LOG记录每次作业的执行历史。分为两个步骤:
1. 作业开始执行时向数据库插入数据,除failure_cause和complete_time外的其他字段均不为空。
2. 作业完成执行时向数据库更新数据,更新is_success, complete_time和failure_cause(如果作业执行失败)。
JOB_STATUS_TRACE_LOG记录作业状态变更痕迹表。可通过每次作业运行的task_id查询作业状态变化的生命周期
和运行轨迹。
4.2 运维
elastic-job中提供了一个elastic-job-lite-console控制台
设计理念
1. 本控制台和Elastic Job并无直接关系,是通过读取Elastic Job的注册中心数据展现作业状态,或更新注册中心
数据修改全局配置。
2. 控制台只能控制作业本身是否运行,但不能控制作业进程的启停,因为控制台和作业本身服务器是完全分布
式的,控制台并不能控制作业服务器。
主要功能
1. 查看作业以及服务器状态
2. 快捷的修改以及删除作业设置
3. 启用和禁用作业
北京市昌平区建材城西路金燕龙办公楼一层 电话:400-618-9090
4 . 跨注册中心查看作业
5. 查看作业运行轨迹和运行状态
不支持项
1. 添加作业。因为作业都是在首次运行时自动添加,使用控制台添加作业并无必要。直接在作业服务器启动包
含Elastic Job的作业进程即可
具体搭建步骤如下:
下载地址:https://raw.githubusercontent.com/miguangying/elastic-job-lite-console/master/elastic-job-lite-
console-2.1.4.tar.gz
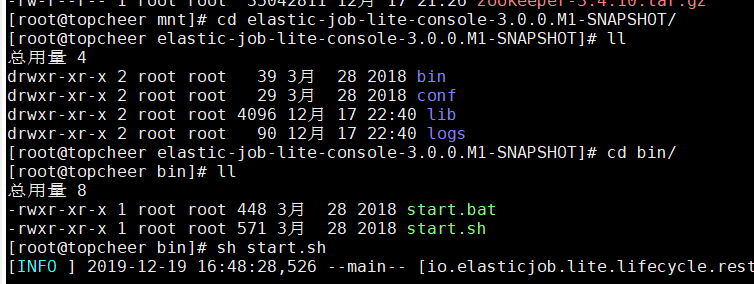
解压缩 elastic -job-lite-console-${version}.tar.gz 。
进入 bin目录 并执行:
打开浏览器访问 http://localhost:8899/ 即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端
口号。
elastic -job-lite-console-${version}.tar.gz 也可通过 elastic-job 源码用 mvn install编译获取
配置及使用
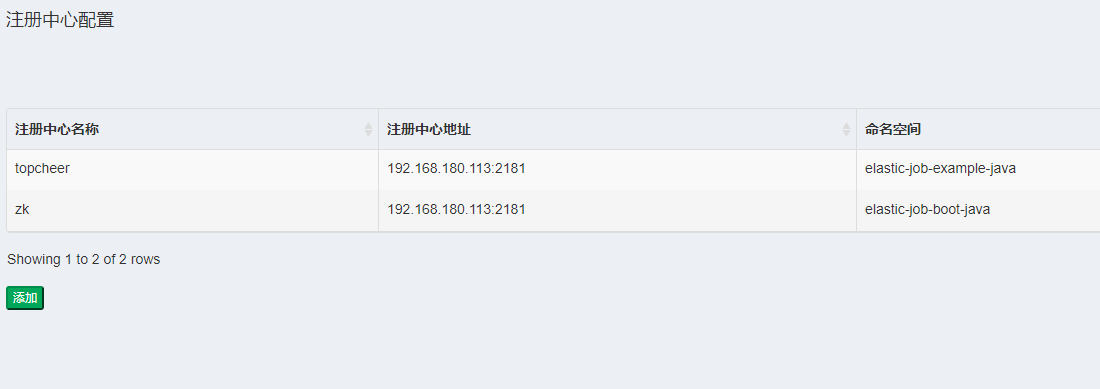
1、 配置注册中心地址
先启动zookeeper 然后在注册中心配置界面 点添加
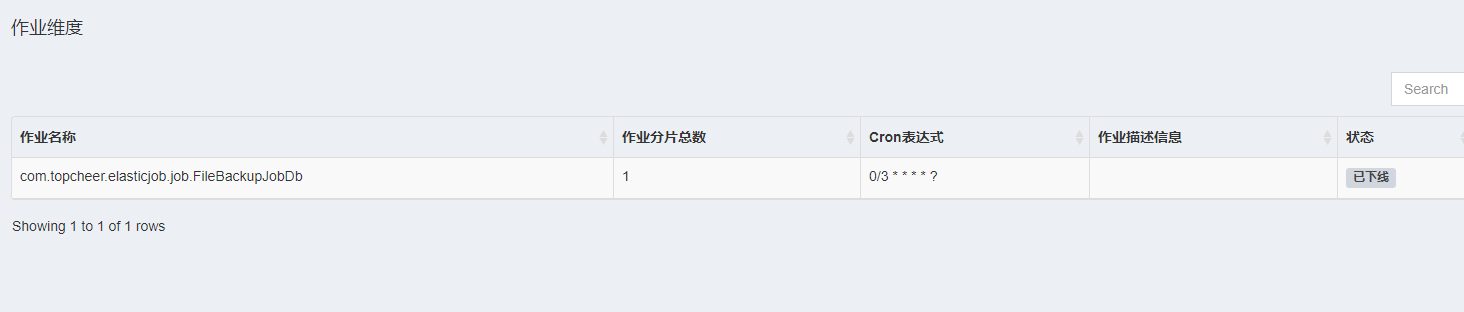
连接成功后,在作业维度下可以显示该命名空间下作业名称、分片数量及该作业的cron表达式等信息
在服务器维度可以查看服务器ip、当前运行的实例数、作业总数等信息。
配置事件追踪数据源
在事件追踪数据源配置页面点添加按钮,输入相关信息
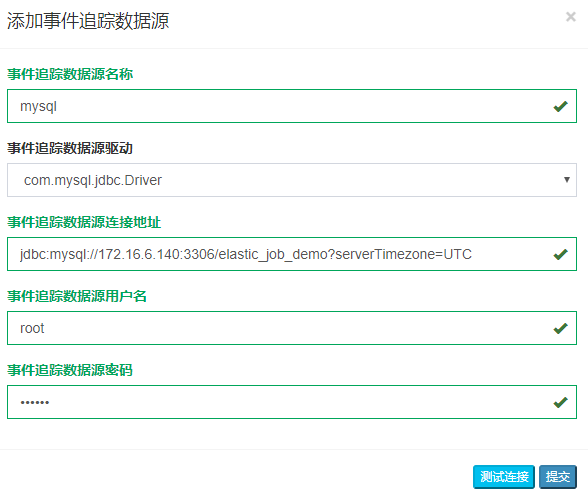
由于本地ipping不同,因此就不能查看详细的日志