- A+
一、对于Map集合存储结构的理解
首先介绍以HashMap为典型代表的Map集合的存储结构
① Map中的key:无序的、不可重复的,底层使用Set集合存储key;key所在的类要重写equals()和hashCode() 。
② Map中的value:无序的、可重复的,底层使用Collection集合存储value;value所在的类要重写equals() 。
③ Map中的entry:无序的、不可重复的,底层使用Set集合存储entry,每个entry都相当于一组
key-value 。
二、HashMap的常用方法
如果想要使用HashMap,我们需要对HashMap的常用方法有一个基本的了解:
* 添加:put(Object key,Object value)
* 删除:remove(Object key)
* 修改:put(Object key,Object value)
* 查询:get(Object key)
* 长度:size()
* 遍历:keySet() / values() / entrySet()
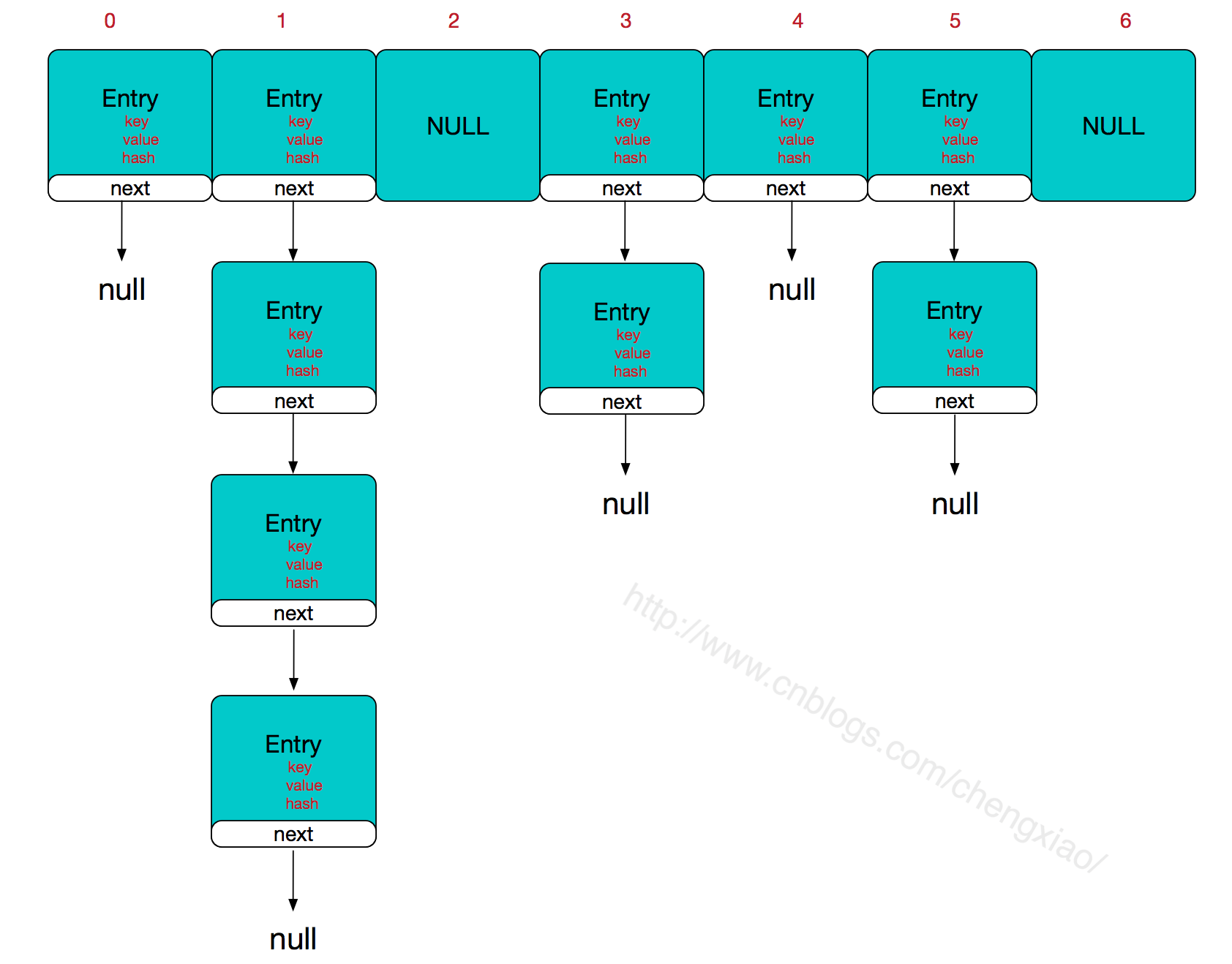
三、HashMap的内存结构说明
① HashMap在jdk7中的实现原理
HashMap对象在实例化后,底层创建了一个长度为16的一维数组 Entry[ ] table
当执行方法 put(key1,value1) 添加数据时,HashMap底层的实现原理如下(此前可能已经执行过多次put()方法):
首先,调用key1所在类的hashCode()计算key1的哈希值,此哈希值经过底层算法的计算以后,可以得到在Entry数组中的存放位置,接下来又分为三种情况。
情况1:如果此位置上的数据为空,此时的key1-value1添加成功。
情况2:如果此位置上数据不为空(意味着此位置上存在一个或多个数据(多个数据以链表的形式存在)),则比较key1和已经存在的数据的哈希值,如果key1的哈希值与已经存在的数据的哈希值都不相同,此时key1-value1添加成功,即key1-value1和原来的数据会以链表的形式存储。
情况3:与情况二类似,在比较key1和已经存在的数据的哈希值时,如果key1的哈希值和某个已经存在的数据(如key2-value2)的哈希值相同,则调用key1所在类的equals()方法,返回key1和key2的比较结果,如果返回的是false,此时key1-value1添加成功,同样也是和原来的数据以链表的形式存储;如果返回的是true,则会使用value1替换value2。
在不断添加数据的过程中,会涉及到数组的扩容问题。当添加数据超出临界值(且数据要存放的位置非空)时,需要对数组扩容。默认的扩容方式:扩容为原来容量的2倍,并将原来的数据复制过来。
② HashMap在jdk8中相较于jdk7在底层实现方面的不同
(1). 使用空参构造器创建HashMap对象时,底层没有直接创建一个长度为16的数组。
(2). jdk8底层存储数据的数组使用的是Node[ ],而不是Entry[ ] 。
(3). jdk8在首次调用put()方法时,底层才会创建长度为16的数组。
(4). jdk7中底层存储数据的结构是:数组+链表。jdk8中底层存储数据的结构是:数组+链表+红黑树。
(5).当存储数据形成链表时,链表的结构不相同,jdk7的链表结构是:新的数据指向旧的数据。jdk8的链表结构是:旧的数据指向新的数据。
(6).当底层数组的某一个索引位置上的元素以链表形式存在的数据个数大于8 ,且当前数组的长度大于64时,此时这个索引位置上的数据改为使用红黑树存储。
四、HashMap底层重要属性的说明
DEFAULT_INITIAL_CAPACITY:HashMap的默认容量:16
DEFAULT_LOAD_FACTOR:HashMap的默认加载因子:0.75
threshold:扩容的临界值 = 容量 * 填充因子:16 * 0.75 = 12
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:Bucket中Node被转化为红黑树时最小的Hash表容量:64