- A+
创建合适的索引,尽量少地访问数据库资源,是数据库结构设计需要考虑的内容。
场景
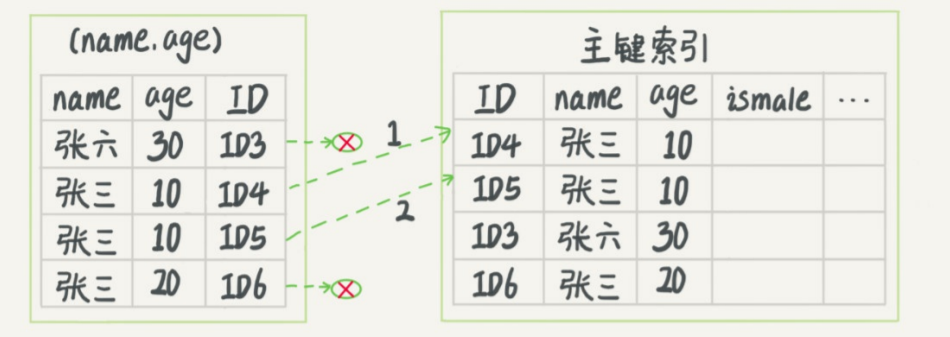
在一个市民信息表上,身份证号码是市民的唯一标识。
Mysql 系列 | 索引(唯一索引 or 普通索引)中讨论了给身份证号建立索引,即可根据身份证号找到对应的市民详细信息。
如果现在有一个高频请求,要根据身份证号查询姓名,这时候建立一个(身份证号、姓名)的联合索引,是不是浪费空间?
如果还要根据身份证号查询家庭地址,是不是还要建一个(身份证号、地址)的联合索引呢?
索引是怎么查数据的
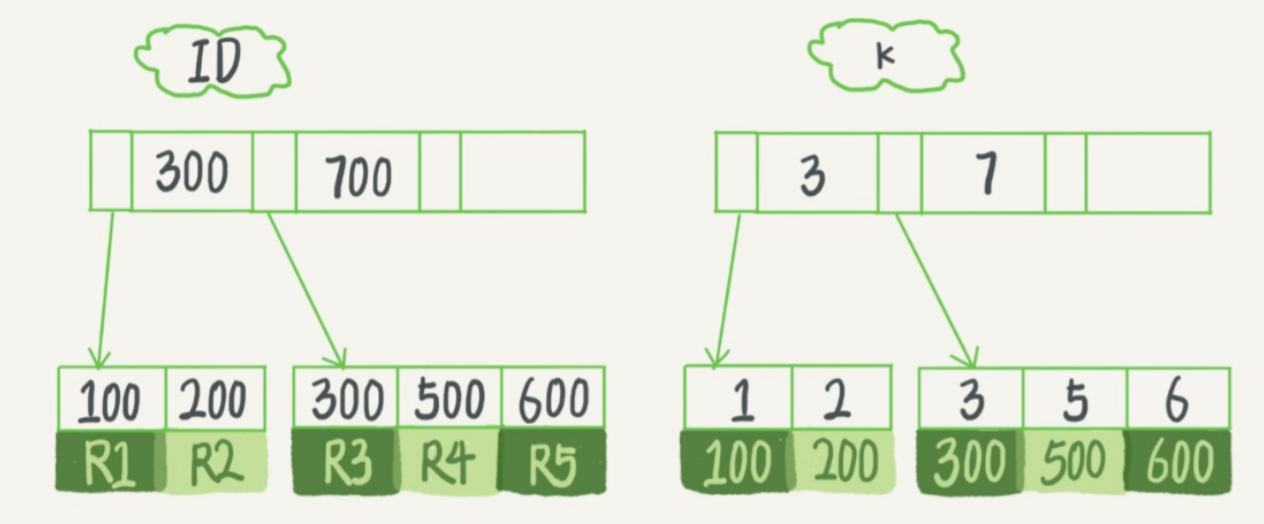
select * from T where k between 3 and 5
(丁奇原图)
在索引树中,索引项都是按照索引列的值按顺序存放的,上面查询的执行顺序如下,
第 1 步、在 k 索引树找到 k=3 的记录,找到 ID=300
第 2 步、在 ID 索引树找到 300 对应的 R3
第 3 步、在 k 索引树取下一个记录 k=5,取到 ID=500
第 4 步、去 ID 索引中找到 ID=500 对应的 R4
第 5 步、在 k 索引树中取下一个 k=6,不满足条件,结束。
整个过程中,读了 k 索引树的三条记录,回表了两次(拿到 ID,回到主键索引树搜索的过程称为回表)
因为 R 信息只有主键索引上有,所以不得不回表查找
也就是说,如果查询的内容在 k 索引树上,则不需要回到主键索引树上找
覆盖索引
select ID from T where k between 3 and 5
-
上面的 SQL,只需要取 ID,而 ID 在 k 索引树上,索引不需要回表。也就是说 k 索引树已经覆盖了查询需求,称为覆盖索引
-
覆盖索引减少了树的搜索次数,是常用的性能优化手段
-
在引擎内部,索引 k 上查了三条记录,而 server 层只拿到 2 条。所以扫描行数是 2。
-
开头场景中,建立(身份证号、姓名)的联合索引,可以在高频请求上用到覆盖索引,大大减少了回表查找整条数据,提高查询性能。
-
索引字段的维护是有代价的,建立冗余索引来支持覆盖索引需要权衡考虑
最左前缀原则
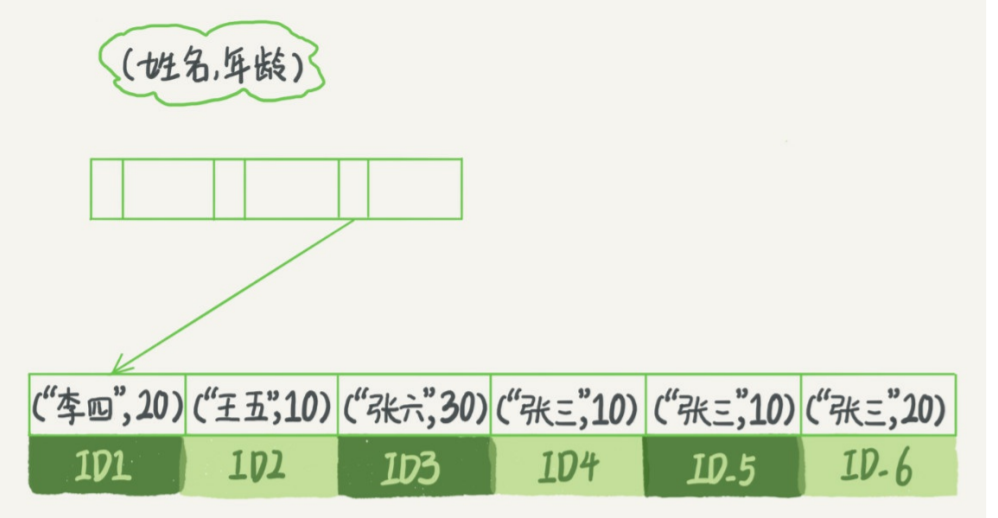
B+ 树索引结构,恶意利用索引的最左前缀进行检索。
(丁奇原图)
-
要查找名字是“张三”的人时,可以快速定位到 ID4,然后向后遍历找到所有数据
-
要查找名字中第一个字是“张”的人时,
where name like "张%"也可以用到索引快速定位到 ID3,向后遍历直到不满足条件为止 -
最左前缀,可以是字符串的最左 N 个字符,也可以是联合索引的最左 M 个字段
-
建立联合索引时,考虑索引的复用能力(字段大小、最左原则),合理安排索引字段顺序
-
开头场景的问题,我们为高频请求建立(身份证号,姓名)的联合索引,同时用最左前缀原则满足身份证号查询地址的需求
索引下推
select * from tuser where name like '张%' and age=10 and ismale=1;
tuser 表中建立了(name、age)联合索引,name like '张%',名字条件可以遵循最左前缀原则进行查询。但是后面还有两个条件怎么办呢!!
-
Mysql5.6 之前,查到名字开头是“张”的数据后,只能回表查到其他整行数据,再比较判断后面的条件是否满足
-
5.6 之后,引入了索引下推,在索引遍历时,同时判断后面的条件是否满足,不满足直接过滤。下图中,InnoDB 在索引(name、age)中,直接过滤了 age != 10 的数据,减少了回表次数